
БИП Бизнес-Процессы, FAQ: Ответы на вопросы, Часть 06
Часть 6
Общий, главный раздел с ответами на вопроcы доступен по ссылке:
Надеемся, данная информация окажется для вас полезной
- БИП Бизнес-Процессы, FAQ: Ответы на вопросы, Часть 01
- БИП Бизнес-Процессы, FAQ: Ответы на вопросы, Часть 02
- БИП Бизнес-Процессы, FAQ: Ответы на вопросы, Часть 03
- БИП Бизнес-Процессы, FAQ: Ответы на вопросы, Часть 04
- БИП Бизнес-Процессы, FAQ: Ответы на вопросы, Часть 05
- БИП Бизнес-Процессы, FAQ: Ответы на вопросы, Часть 06
- БИП Бизнес-Процессы, FAQ: Ответы на вопросы, Часть 07
- Настройка контроля ценообразования
- Размер базы
- Разные настройки задач
- Использование генеративной модели
Думаю в этом моменте один из важных вопросов, использовать или не использовать Вашу систему. Потому что буквально на прошлой неделе приходилось удалять около 10 млн записей по истории изменений документов, 18-22 й года. Есть предположение, что Ваша система будет большой вклад делать в размер базы.
- В историю изменений по умолчанию система ничего не пишет,
- Часть служебных данных система удаляет автоматически (очистка регистров сведений событий - по умолчанию раз в 2 недели),
- Временные служебные данные, связанные с действующими, но не завершенными процессами, удаляются, когда процесс завершается (промежуточные данные, требуемые только когда процесс действующий, но которые не требуются ни в каком виде, когда он завершен),
- Регистр сведений "Лог", в котором фиксируются результаты обработки событий и запущенные по событиям процессы можно очищать вручную - здесь автоматической очистки нет.
- За много лет каких-то отдельных обращений по поводу того, что база критично выросла за счет данных подсистемы, к нам не поступало. Раньше были обращения как раз связанные с просьбами автоматической очистки служебных регистров, о которых написано выше и которые мы в последствие включали в обновления.
В том числе, такие обращения не поступали и от клиентов с количеством пользователей от 100 и выше. - Вообще, в системе используется минимально необходимый набор объектов метаданных. Т.к. изначально система проектировалась как универсальное решение для подключения в любые конфигурации, поэтому состав и объем метаданных не "раздувался".
В дополнение ниже приведен пример увеличения размера небольшой демонстрационной базы, в которую загружена подсистема КонструкторБизнесПроцессов.
Первоначальный размер базы: 39Мб

В программе создан простой сценарий, состоящий из 1 задачи.
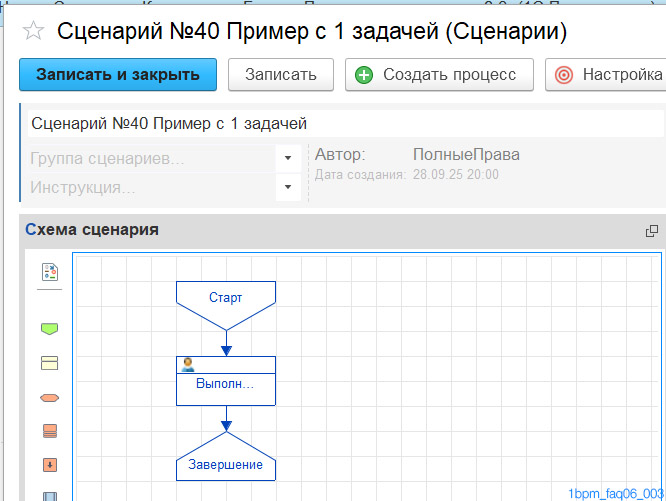
По сценарию запускается процесс. По процессу формируется задача "Выполнить действие". После завершения задачи процесс завершается.
Для примера программно было запущено 999 процессов по данному сценарию.
После запуска процессов размер базы увеличился до 41Мб:

Затем, программно задачи были выполнены. После их выполнения процессы завершились.
После этого размер базы увеличился до 46Мб:

999 завершенных процессов:

999 завершенных задач:
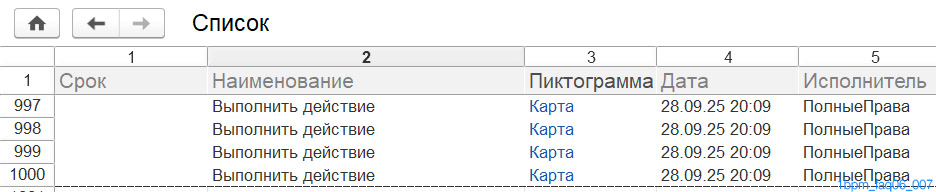
По данному примеру можно условно судить о том, насколько увеличивается база при: 1000 завершенных задач.
Например идентификатор из объекта не являющегося источником сценария.
Дайте пожалуйста пример или отсылку на мануал где подобный вопрос разобран.
Так же интересуют моменты
- программное (или средствами БИП) управление сроками исполнения задач,
- возможность программного завершения задачи извне,
- завершение задачи по сроку истечения годности (например: пользователь задачу не выполнил, клиент обратную связь не дал, на исполнение было 2 недели. на 15й день задача автоматически уходит в "отклонено").
Вместе с системой
![]() КонструкторБизнесПроцессов
может поставляться автономный сервер для работы с генеративной моделью (Автономный ИИ).
Этот сервер может использоваться автономно (т.е. без обращения к внешним сервисам) для интеллектуального поиска/классификации/сравнения данных (поиск по векторному пространству), а также для генерации текстовых ответов по произвольным запросам.
КонструкторБизнесПроцессов
может поставляться автономный сервер для работы с генеративной моделью (Автономный ИИ).
Этот сервер может использоваться автономно (т.е. без обращения к внешним сервисам) для интеллектуального поиска/классификации/сравнения данных (поиск по векторному пространству), а также для генерации текстовых ответов по произвольным запросам.
Генерация ответов может использоваться не только (и не столько) для целей отправки конечным пользователям готовых текстов, сколько для использования результатов генерации для встраивания в бизнес-процессы.
В первую очередь это может касаться процессов, в рамках которых неформализованные текстовые данные могут оказаться важными для анализа и обработки.
В качестве самого простого примера использования можно привести обработку входящих писем.
Для примера создадим простой сценарий, который запускается при появлении в информационной базе нового электронного письма.
*Пример показан в рамках конфигурации УНФ, где электронное письмо - это объект "Событие" с видом "Электронной письмо".
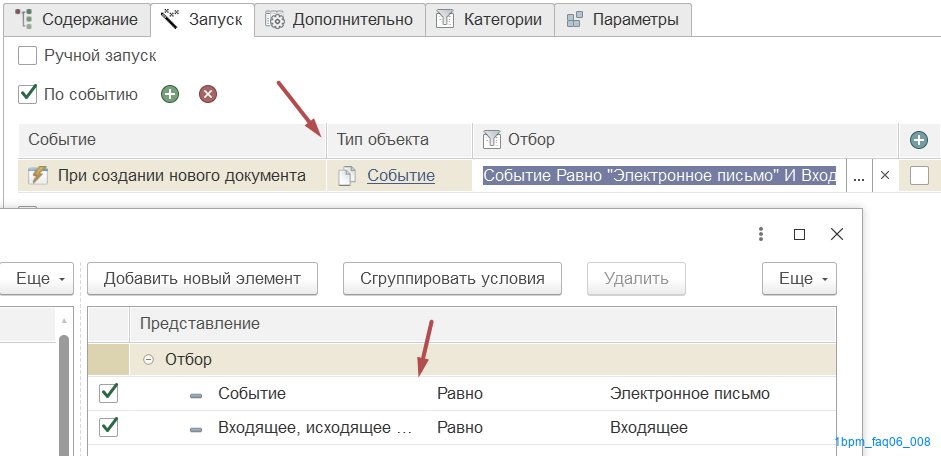
Сам процесс будет состоять из одной проверки и задачи, которая должна будет сформироваться для пользователя, если содержание письма будет касаться задержки сроков доставки.
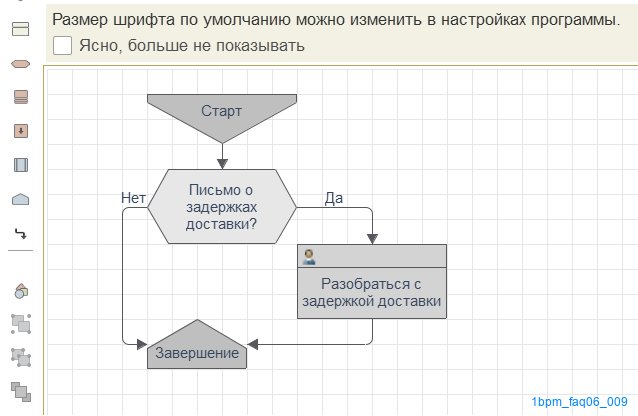
В коде проверки выполним готовый алгоритм, вызвав его имени:
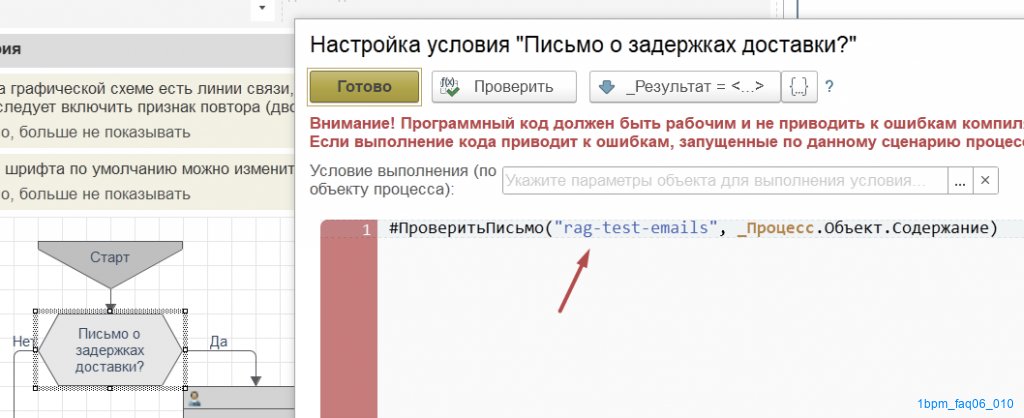
Здесь #ПроверитьПисьмо - это вызов алгоритма. В качестве параметров передадим имя готовой настройки и текст письма (т.к. процесс запускается по электронному письму, то к нему мы можем обратиться через _Процесс.Объект).
Если проверка вернет _Результат=Истина, значит ИИ посчитал, что это письмо о задержках доставки и, следовательно, надо будет создать задачу для исполнителя.
*Здесь в примере мы исполнителя не указываем.
Сам алгоритм содержит программный код, который подключается к нашему автономному серверу по адресу и порту, отправляет ему данные и обрабатывает полученный ответ.
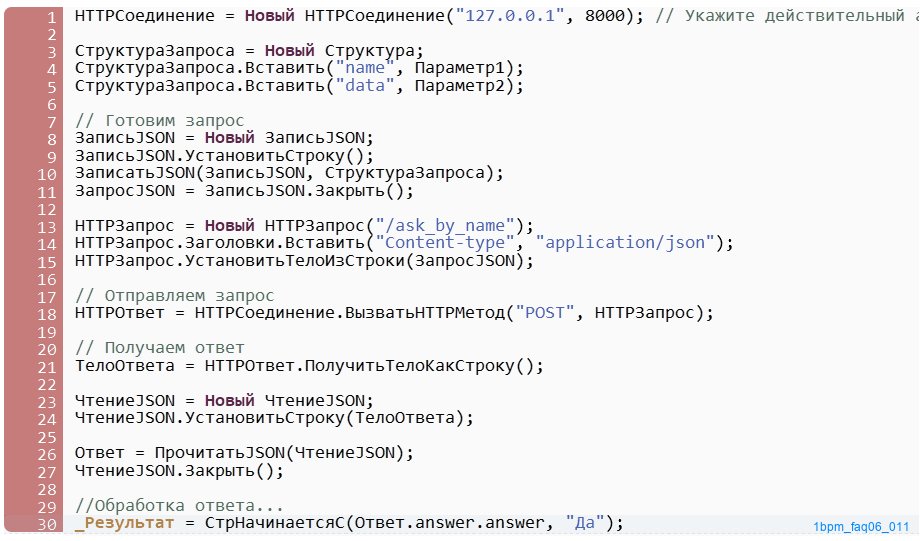
Параметр1 мы передаем в качестве имени готовой настройки.
Параметр2 - это данные, на основании которых генеративная модель будет формировать ответ.
Парсинг готового ответа здесь самый простой - главное, чтобы он передавал суть.
Чтобы можно было обращаться к данному алгоритму внутри другого программного кода, укажем его имя.

Сценарий готов. Когда мы его активируем, система будет "слушать" события создания электронных писем.
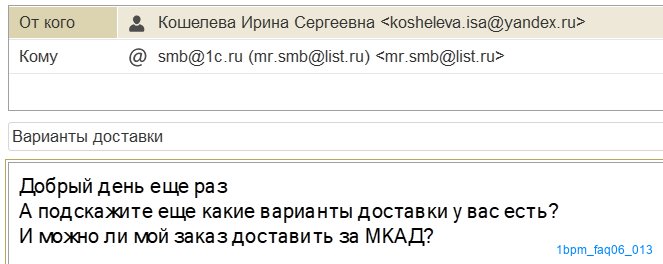
По такому входящему письму, очевидно, ответ будет "Нет" и задачу по разбору ситуации с задержкой доставки создавать не придется.
Пример письма взят из демо-базы УНФ.
Сам процесс будет выглядеть таким образом:
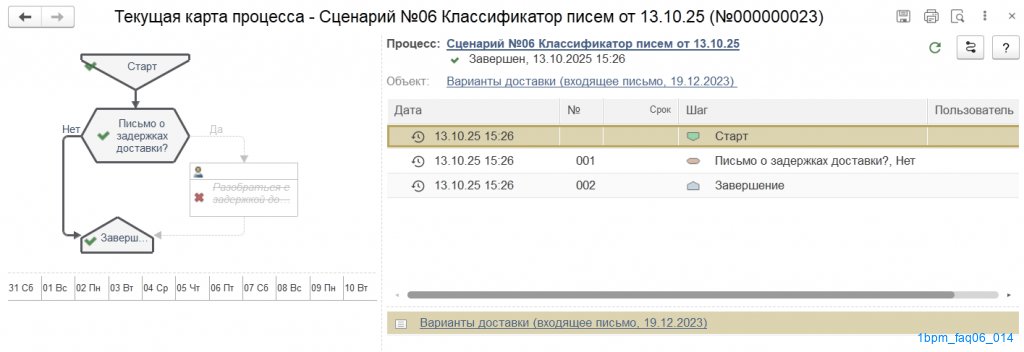
Теперь осталось только дождаться, пока в базе появится письмо о реальной задержке сроков.
Все предварительные настройки, которые позволяют затем обращаться к модели, делаются во внешней обработке Консоль RAG, поставляемой вместе с автономным ИИ.
См. Руководство пользователя «Консоль RAG».pdf
Консоль используется для:
- Тестирования работы RAG-пайплайна с различными параметрами ретривера и RAG-генератора (генеративной модели).
- Настройки и сохранения конфигурационных данных, которые в дальнейшем могут быть использованы в программных вызовах по их имени.
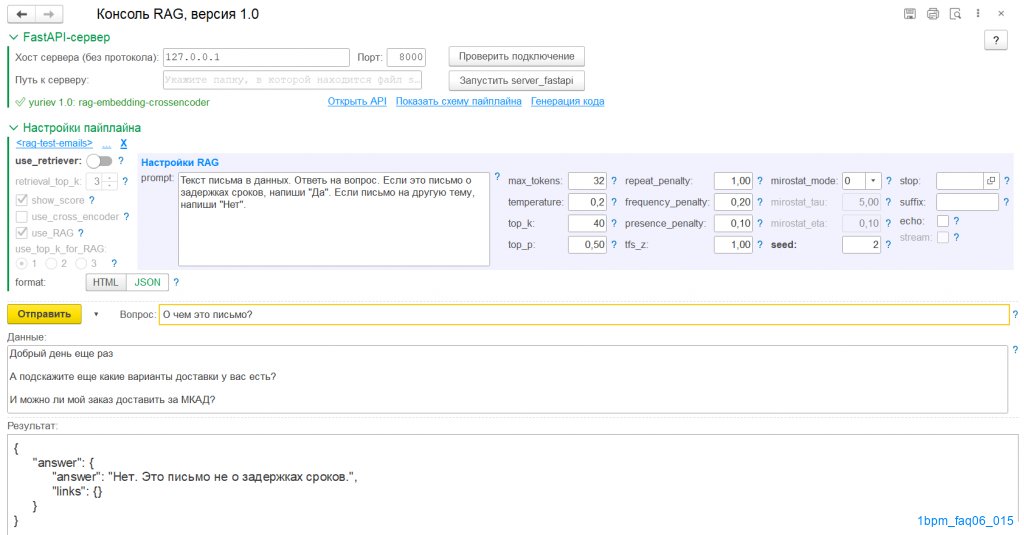
Здесь мы можем предварительно протестировать промпт, различные параметры модели, сохранить их, а затем обращаться к ним из любого места напрямую по имени сохраненной настройки.
Именно так мы и сделали, когда настраивали сценарий.
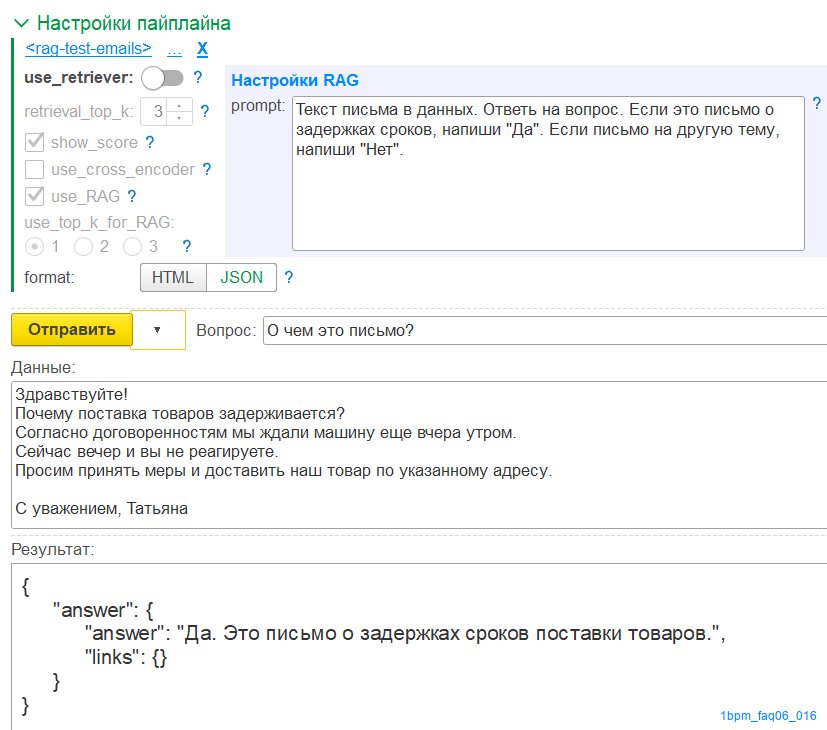
Здесь же, чтобы протестировать работу модели, можно указать текст другого письма и проверить, что ответит ИИ:
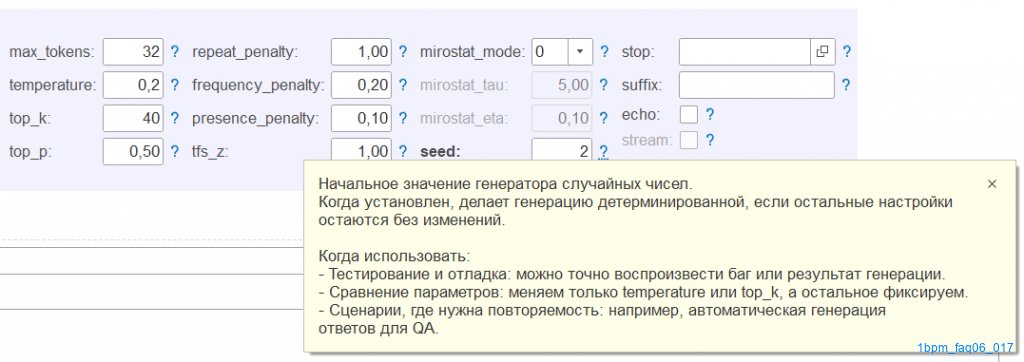
Для того, чтобы добиться от модели максимально возможного релевантного "поведения", кроме написания промпта можно отрегулировать параметры генерации:
Все настройки сохраняются на автономной сервере, поэтому никаких дополнительных настроек в самой информационной базе делать не требуется.
Затем, при использовании сохраненной настройки мы просто можем передать Данные (из значимых объектов системы - в нашем примере это текст письма), а сервер по промпту и тексту вопроса сгенерирует ответ, который мы сможем уже использовать дальше, выстраивая логику бизнес-процесса.
Также, здесь есть пункт меню, который позволяет сгенерировать готовый программный код 1С для подключения к серверу.
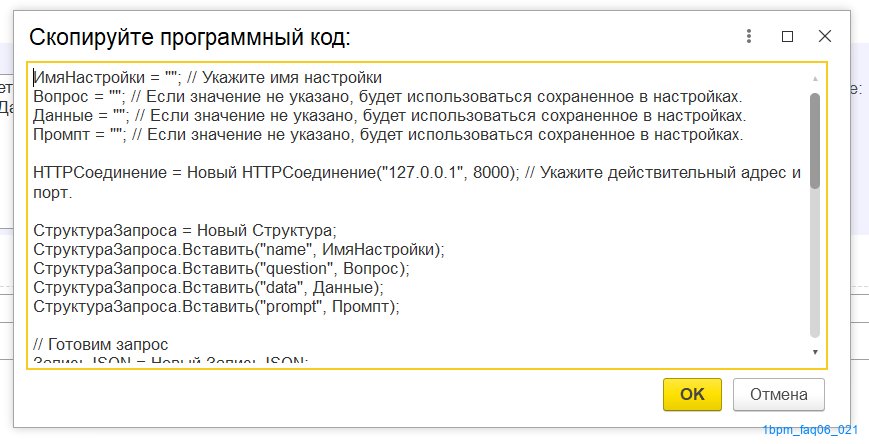
Этот код можно просто скопировать и использовать:
Дополнительная информация об автономном пайплайне доступна по ссылке: Автономный RAG-пайплайн